训练营是什么
- 这个训练营要训练你掌握一套人机高效协同的综述论文工作流。我们不让 AI 取代你思考,而是把它当成一名不知疲倦的科研助理,把你从检索、筛选、标注、归类、排版这些繁琐重复的机械劳动里解放出来,让你能把精力真正花在学术判断、逻辑框架和成果把控上。
- 整个训练过程是我【钟教授、国家杰青、全球高被引科学家、TOP期刊(影响因子20+)副主编】和刘老师团队专门设计的。全程由刘老师团队一对一陪跑,针对你每一期的训练作业给出可落地的反馈,直到你一期期往下推进,获得最终的论文。我会全程旁观监督,关注刘老师团队的每一次训练批注,如果发现团队的反馈还有可补充之处,我也会进一步补充。可免费体验3天!
- 为了让你理解“参加训练之后到底能拿到什么”以及整体的训练安排,下面我们用一篇真实投稿的皮肤癌综述作为贯穿案例:起点只是一个中等颗粒度的关键词——皮肤肿瘤细胞表征,终点是一篇聚焦于“电阻抗谱(EIS)技术在皮肤癌诊断中的应用与临床转化”、结构完整、逻辑清晰、逐句经过事实核查且没有新手常见的“综而不述”问题的综述论文。你会看到每一步的真实中间产出。
- 建议把这页当成一张“地图”:先看四阶段全景建立整体认知,再顺着案例实战逐步深入,做作业时随时对照——清楚每一步的目的,以及它要为下一步准备什么材料,就不会在流程里迷失焦点。
新手如何开始?
操作指南
- 为尽可能提高大家的获得感,请务必仔细阅读并遵循以下操作指南:
- 在 PC(电脑)端打开浏览器,访问:
https://wx.zsxq.com/,或自己输入 wx.zsxq.com。 - 按照提示用微信扫码登录。如果登录有问题,可以用微信扫描下方二维码加入。
- 开始前先备好“兵器”:本训练营的多个自动化环节由一个桌面小程序——《论文处理工具箱》承担。建议你在正式开课前,先到工具箱章节熟悉它的四大功能并下载好,后续每一步我们都会标注“该用哪个功能”。

四阶段全景
先把整张地图看清楚。整个流程分四个阶段、十余个步骤,每一步都有明确的“输入 → 产出”。下面这四张卡,就是你接下来要走完的全部路程。
从一个宽泛的想法出发,借 AI 精准定位到一个既有创新性又可行的具体选题(如果你已经有具体选题,那么就用你的),并为它建好一个高相关的核心文献库。
把无序的文献库,变成一份逻辑严密、章节分明、且每个子章节都有足量文献支撑的写作蓝图,并让每篇文献都“各就各位”。
在 AI 辅助下完成初稿,再通过系统化流程做语言修改、事实核查、原创性重塑,把“AI 味”的草稿内化成真正属于你的表达。
完成配图、版权、参考文献格式化等全部收尾,交付一份可以直接投稿的成品。
案例实战:一篇皮肤癌综述的诞生
下面顺着四个阶段走一遍。每个步骤都按同样的格式呈现:这一步做什么 → 你会拿到什么 → 展开看原始产出(节选)。
泛检索式生成:把一个关键词,变成专业检索式
这一步做什么:你只提供一个中等颗粒度的关键词——本例是“皮肤肿瘤细胞表征”。用我们专门设计的 AI 提示词,把它自动拆成三个可检索的核心概念(皮肤 / 肿瘤 / 表征所对应的“无创检测技术”),并补全每个概念的同义词、英文变体与缩写,最后拼成一条专业的高级检索式。
一条可直接粘贴进 Scopus 的高级检索式(也会教你改造后用于其他比如WOS、PubMed、CNKI等数据)。它的任务,是把这个中等颗粒度领域下的综述论文尽可能“一网打尽”,作为后续 AI 分析、寻找细分选题的弹药。
展开看本案例的真实检索式(综合全面型)
AI 先给出两个方案——“综合全面型”与“核心技术聚焦型”。下面是方案一(综合全面型,推荐首选):把“表征”落到当前皮肤肿瘤领域最主流的一批无创检测技术上,并刻意保留 lesion*(病变)以覆盖癌前阶段文献:
TITLE-ABS-KEY (
( skin OR cutaneous OR dermal ) AND
( tumor* OR tumour* OR cancer* OR carcinoma* OR melanoma*
OR neoplasm* OR malignan* OR lesion* ) AND
( "non-invasive" OR noninvasive OR "in vivo" OR dermoscop*
OR dermatoscop* OR "reflectance confocal microscopy" OR RCM
OR "optical coherence tomography" OR OCT OR "Raman spectroscop*"
OR "hyperspectral imaging" OR "photoacoustic imaging"
OR "high-frequency ultrasound" OR "terahertz imaging" )
)
AND NOT TITLE ( review OR "case report" OR "case series" )第二组 (tumor* OR …):这里我们增加了一个非常重要的词 lesion*(病变),因为很多无创检测技术的目标是在疾病早期、甚至癌前病变阶段进行诊断,使用“病变”一词能更好地捕获这些文献。
重要调整:我们没有在这里排除 therap*(治疗)或 treat*(处理)——因为很多无创检测技术的研究目的就是为了“监测治疗反应”,例如用 OCT 观察肿瘤在治疗过程中的变化,排除这些词会错失大量重要的应用研究文献。 ……
投库,并按“综述数量”决定下一步
这一步做什么:把检索式投进数据库,先看一眼 Review 类型论文的数量,再对照下面这套“红绿灯”规则行动。颗粒度合不合适,数字会替你说话。
一个明确的“下一步动作”——是直接进入选题分析,还是先调整检索范围。颗粒度被校准到刚刚好。
展开看“综述数量”判断规则
综述 ≥ 50 篇:领域积累已很充分,直接进入第 3 步建库。
综述 10–50 篇:最理想的区间——既能反映现状又不会信息过载。直接进入第 3 步,或额外补充少量高质量研究型论文一起分析。
综述约 10 篇:偏少但仍有基础。建议把检索到的研究型论文也一并纳入,给 AI 更丰富的输入。
综述只有几篇,或结果总数 < 100 篇:说明颗粒度其实已经偏细了。两种处理办法——① 退回上一层级,砍掉一个关键词、扩大检索范围;② 直接切换到“最细颗粒度”的分支流程(此时你的选题颗粒度已接近最细)。
结果总数过多(> 1000–2000 篇):不用慌,AI 后续完全处理得了。若想精简输入,可在数据库层面加限制——只留近 5 年、只留 Q1/Q2 分区、或只留特定顶刊(视频里有演示)。
批量导出 RIS,导入 Zotero 搭起初步库
这一步做什么:在 Scopus(或其他文献搜索引擎) 里把目标综述批量导出为含摘要的 RIS 文件,导入 Zotero,按标准化流程整理成库。
一个在 Zotero 里整整齐齐、与你方向相关、每篇都带完整摘要的综述文献库——为下一步 AI 领域分析备好原料。
AI 领域分析,挖出“研究空白”与具体选题
这一步做什么:从 Zotero 导出全部综述的元数据,喂给 AI 的领域分析提示词,让它读完这上百篇综述、勾画出领域的热点与空白,再给出几个具体到可以直接动笔的选题方向。
3–5 个候选选题,每个都附带“为什么这个角度还没被充分综述”、“大致的文献组织思路”、“预估的工作量与难度”。你再结合研究兴趣、与课题组已有工作的契合度、导师意见,敲定最终选题——这就是整篇综述真正的“干货内核”。
展开看 AI 给出的 3 个候选方向,以及最终选定的主题
方向一:AI 赋能下的阻抗谱技术(首选推荐)
(1) 具体标题建议:《人工智能如何解锁电阻抗谱的诊断潜力:皮肤肿瘤领域的应用、算法与挑战》
(2) 为什么这个角度还没被充分综述:文献列表明确显示,将 EIS 与 AI 结合是近年来的绝对前沿。现有综述要么宽泛地谈论皮肤癌的无创技术,要么单独综述 AI 在皮肤镜图像中的应用。专门剖析“EIS 复杂电学数据”与“AI 高级算法”这一特定“强强联合”的综述仍然是一个空白。
(4) 预估的工作量和难度:工作量中等,核心文献相对集中,大约 30–50 篇;难度中等偏高,难点在于清晰阐述算法与数据的结合方式,并提出有见地的技术评述。 ……(另含 方向二:跨癌种应用的比较性综述;方向三:临床转化与实用性聚焦,此处略)
矩阵式精准检索,囤好写作“弹药库”
这一步做什么:围绕已定选题,用“矩阵式检索”提示词把主题拆成多个核心概念,做多层次组合检索,再通过“检索 → 分析 → 优化”的循环不断迭代,把噪音一轮轮挤出去。
100–600 篇与最终选题高度相关的研究型论文——这就是你后面要精读、提炼、引用的弹药库。
展开看矩阵式检索的拆解与迭代实况
选题被拆成四个核心概念,各自建好“语义群”,再用 AND 组合:
A 阻抗谱(impedance spectroscopy / EIS / bioimpedance…)
B 皮肤癌(skin cancer / melanoma / BCC / SCC…)
C 临床(clinical / patient / diagnosis / screening…)
D 人工智能(AI / machine learning / deep learning / SVM…)
A AND B AND C AND D → 最精准的核心交叉(综述主体支柱)
A AND B AND C → 回溯 AI 出现前的传统临床证据(写引言/背景)
B AND C AND D → 对照皮肤镜图像 AI 的主流水平(写讨论)
A AND C AND D → 借鉴其他癌种“阻抗+AI”的成熟范式(写方法/展望)检索 → 分析 → 优化(真实一幕):首轮结果混进了腐蚀、电池、麻醉的文献。AI 自查后给出原因——
为什么会检索出不相关的文献?(AI 自查节选)
· lesion*(损伤、病变):在材料科学和腐蚀领域,lesion 常用来描述材料表面的腐蚀坑或损伤点……
· “BIS”:除了代表“生物阻抗谱(Bioimpedance Spectroscopy)”,它更常用于麻醉领域,代表“脑电双频指数(Bispectral Index)”。
· dermatolog*(皮肤病学):涵盖了痤疮、湿疹、皮肤屏障等所有皮肤研究,与癌症无关,是噪音的主要来源,强烈建议删除。 ……
据此 AI 产出“平衡版 / 严格版”两套优化检索式,再跑一轮——这就是循环迭代的实况。
阶段一小结:跑完前 5 次训练,你手里多出了什么
一句话——你为整篇综述打好了地基。后面所有的大纲、写作、配图,都长在这块地基上:
相关度分级 + 数据驱动的写作大纲
这一步做什么:先用工具箱的论文分割器把上百篇文献切成 AI 能一次“吃下”的小批量;让 AI 分批给每篇文献评相关度等级(A/B/C/D),筛掉真正不相关的;再让 AI 把保留下来的文献综合聚类,输出一份每个子章节后面都标注了“支撑文献数量”的大纲。
一份结构完整、逻辑清晰、而且经过文献数量验证的可执行写作大纲——哪一节有多少篇文献撑着,一目了然,不会出现“写到一半发现没料”的尴尬。
展开看本案例真实生成的大纲(基于 119 篇 A/B 级文献)
在分析了您提供的 119 篇相关性等级为 'A' 和 'B' 的文献后,我将它们归纳为四个核心技术章节,并进一步细分为八个二级子主题。
—— 拟定题目:电阻抗谱技术在皮肤癌诊断中的应用与临床转化进展
- 皮肤癌流行病学与传统诊断的局限
- 无创/微创诊断的发展趋势
- EIS 基本原理与生物医学应用潜力
- 价值与地位总结 · 主要挑战(标准化/成本/接受度)· 未来研究方向
文献智能打标签:让每篇文献“自报家门”
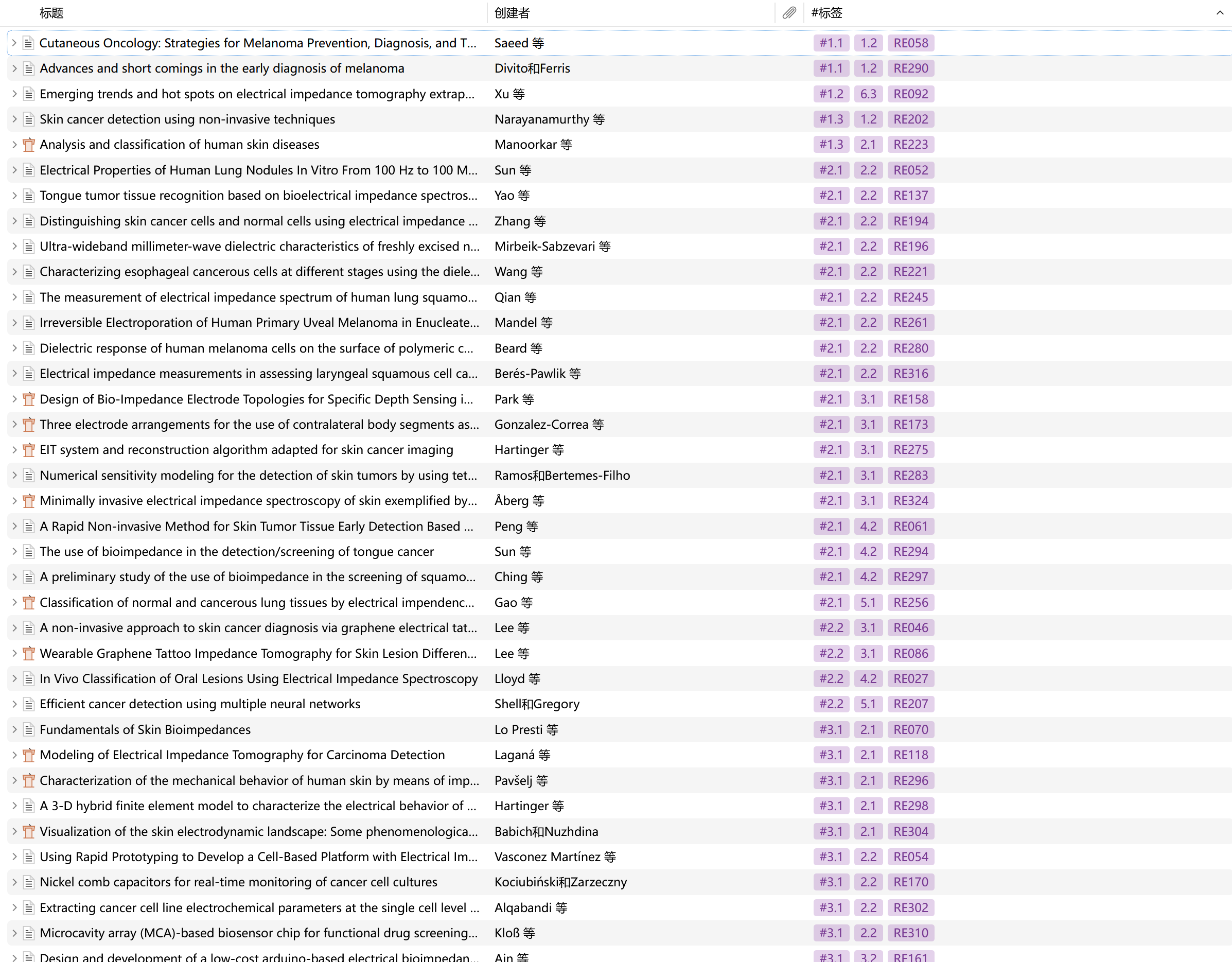
这一步做什么:让 AI 为每一篇文献判断它的主章节、次要章节和核心贡献;然后用工具箱的 BibTeX 标签同步器,把这些章节标签(如 #2.1)和论文的唯一编号(REXXX)一键批量写回 Zotero。
一个在 Zotero 中被完全结构化的文献库:每篇文献后面都跟着“它能用于哪些章节 + 它的唯一编号”。文献管理从此变得无比清爽——再也不用靠记忆和翻找。
分章节智能写作:从“结构化素材”到“段落初稿”
这一步做什么:要写哪一章,就用工具箱的章节筛选器一键筛出该章全部文献 → AI 做第一轮深度分析 → 第二轮论点聚类、生成段落级写作大纲 → 用引用编号补全器为每个段落精准提取要用到的文献素材 → AI 第三轮辅助写作,落成段落初稿。
综述正文各章节的初稿——论点有聚类、每句话有对应文献、引用编号已就位。
展开看一段真实写出来的正文(5.2 多模态融合)
…… The fundamental rationale for this multimodal fusion lies in the distinct biophysical dimensions each technology captures. While EIS provides a highly sensitive, quantitative assessment of cellular irregularity by measuring bulk electrical properties (such as extracellular resistance Re and membrane capacitance Cm), it inherently lacks spatial resolution and cannot generate morphological images [RE214]. Conversely, optical methods provide structural visualization but can be limited by penetration depth or subjective interpretation [RE006]. ……
句末 [RE214]、[RE006] 由引用编号补全器自动带出,到阶段四被脚本一键替换成期刊规范引用。
语言润色 + 事实核查(真实性核查)
这一步做什么:两件事并行—— 一边对标期刊范文做语言润色,一边启动四级匹配度事实核查,把初稿里的每一句话拿回去和它引用的原文摘要或全文中的某处逐句比对,揪出 AI 编造或夸大的地方。这是学术写作“最后一公里”里最不能省的一步。
一份语言地道、且逐句可溯源的精修稿。哪句是文献明确支撑的、哪句要改、哪句是 AI 幻觉,清清楚楚。
展开看真实的事实核查表(节选)
核查严格且仅基于文献摘要,每句话给出四级判定:强匹配 / 部分匹配 / 不匹配 · 幻觉 / N/A。下面摘几行真实结果:
| 原文句子(节选) | 核查结果 | 说明 |
|---|---|---|
| “…Arduino-based EIS system working at 10 Hz–100 kHz with a current of 0.370 mA [RE161]” | 强匹配 | 摘要数据完全吻合(0.370 ± 0.003 mA、10 Hz–100 kHz)。 |
| “…the measurement… takes a short time within 10 seconds [RE215, RE250]” | 不匹配 · 幻觉 | 两篇摘要均未提及“10 秒”这一数据,疑似 AI 杜撰(或藏在全文里需回查)。 |
| “…rigid electrode with approximately 5 × 5 mm active area… [RE250]” | 不匹配 · 幻觉 | 摘要只报告了灵敏度/特异性,完全没有电极尺寸信息。 |
| “Nevisense was classified as Class III… requiring PMA [RE005, RE081]” | 不匹配 · 幻觉 | 两篇摘要均未出现 Nevisense / Class III / PMA 等具体表述。 |
| “As early as 2007, developers recognized regulatory approval was as critical… [RE315]” | 强匹配 | 2007 年原文明确支持此论断。 |
引言、结论与摘要的系统化构建
这一步做什么:用与正文相同的“范文解构 → AI 搭大纲 → 匹配文献 → 辅助写作 → 事实核查”流程,但换上针对引言、结论/展望、摘要的特化提示词,把论文的开篇、收尾和门面一并拿下。
完整的引言、结论与展望、摘要精修稿——和正文同一套质量标准,逐句可溯源。
降 AIGC 率 + 原创性重塑
这一步做什么:掌握“用自己的话给师弟重讲一遍”的核心心法,通过“英文直改”或“中英转换”,并结合我10多年顶刊审稿经验给你制作的专属Checklist(参加训练者可获得这份文件的永久订阅权限,文件会不断更新),把 AI 固有的句式和逻辑流彻底打碎重构,补上你自己的理解和细节。这不只是为了过检测,更是把别人的话真正内化成自己的话。
一篇语言上带有个人风格、AIGC 率显著降低(从动辄 70%+ 降到 10% 乃至更低)、低查重率的稿子。
论文配图策略与版权
这一步做什么:先让 AI 拆解顶刊范文的配图策略,再结合你的全文,生成一份定制化配图计划;然后按计划去找图或自己绘制,并走完引用图片的版权申请流程(含 Elsevier 等出版社的实操)。
一套有说服力、符合规范的论文配图,以及对应的版权授权——不会在投稿前卡在图片版权上。
参考文献自动化,交付终稿
这一步做什么:全文定稿后,把含 REXXX 占位符的 Word 文档、BibTeX 文件和 CSL 样式喂给训练营提供的自动化脚本(RE2CiteKey),一键把所有占位符替换成规范引用、并自动生成文末参考文献列表。(也可以用 Zotero 的 Word 插件“边写边引”。)
一份配图齐全、引用格式完全正确、可直接提交的综述论文终稿。
展开看终稿引言段 + 自动插入的参考文献
…… With the growing incidence of skin cancer that becomes a global public health concern [1,2], more precise and objective tools are urgently needed to address the inherent limitations of current diagnostic methods [3]. At present, the clinical diagnosis of skin diseases usually first uses visual observation assisted by dermoscopy, and invasive biopsy follows to offer further confirmation [4–6]. ……
文末自动生成规范参考文献列表:
References
1. Saeed, W.; Shahbaz, E.; Maqsood, Q.; Ali, S.W.; Mahnoor, M. Cutaneous Oncology:
Strategies for Melanoma Prevention, Diagnosis, and Therapy. Cancer Control 2024, 31, doi:10.1177/10732748241274978.
2. Long, G.V.; Swetter, S.M.; Menzies, A.M.; Gershenwald, J.E.; Scolyer, R.A. Cutaneous Melanoma.
The Lancet 2023, 402, 485–502, doi:10.1016/S0140-6736(23)00821-8.
3. Chatzilakou, E.; Hu, Y.; Jiang, N.; Yetisen, A.K. Biosensors for Melanoma Skin Cancer Diagnostics.
Biosensors and Bioelectronics 2024, 250, doi:10.1016/j.bios.2024.116045.
4. Jutzi, T.; Krieghoff-Henning, E.I.; Brinker, T.J. The Rise of Artificial Intelligence -
High Prediction Accuracy in Early Detection of Pigmented Melanoma.
Laryngo- Rhino- Otologie 2023, 102, 496–503, doi:10.1055/a-1949-3639.
…(其余条目按引用顺序自动补全)核心工具:论文处理工具箱
上面流程里那些“一键完成”的丝滑环节,背后都是它。我们把课程里多个独立小程序整合成了一个桌面应用——《论文处理工具箱》,四大功能各自对应工作流中最容易卡壳的自动化节点。
① 论文分割器
把上百篇文献批量切成 AI 能一次“吃下”的小文件,让大规模相关度分级、领域分析成为可能。
用于 · 阶段二「相关度分级 + 大纲」② BibTeX 标签同步器
把 AI 判好的章节分类一键写回 Zotero,每篇文献自动带上 #章节号 与 REXXX 唯一编号。手动打标签从此退休。
③ 章节筛选器
写某一章时,一键筛出该章所有相关文献,不必在几百篇里翻找——想写哪节,料就在哪节。
用于 · 阶段三「分章节写作」④ 引用编号补全器
按段落大纲,精准提取该段要用到的具体文献信息,让 AI 写作时“言之有据、引之有号”。
用于 · 阶段三「分章节写作」REXXX 占位符的 Word、BibTeX 与 CSL 样式,一键替换全部引用并生成参考文献列表。- 为什么把它做成工具:综述写作真正费时的,从来不是“想”,而是分割、标注、筛选、补编号、改引用这些机械活。把这些交给工具箱,你才能把时间花在判断与表达上——这正是训练营“人机协同、各司其职”理念的落地。建议开课前先下载、跟着手册跑一遍,后续每一步都会更顺。
完整训练清单(作业入口)
下面是全部训练的入口。建议先看完四阶段全景,再依次点开、按说明完成对应作业。每一步点完大概会拿到什么,前面案例里都演示过了——做的时候随时往回对照。
底层逻辑与总览
阶段一 · 从宽泛想法到精准选题与文献库
阶段二 · 从文献库到写作大纲
阶段三 · 正文写作与质量精修
训练怎么做?为什么要提交作业?
- 点开训练作业入口后,务必先完整看完该期视频,再看完整视频简介和作业说明。不要只看文字或只看视频——视频信息密度很高,建议结合暂停和回放。文字加视频都看完,再按部就班操作。
- 点击作业下方的“写作业”提交。注意你做的是哪一期,就在哪一期下方提交,方便刘老师团队精准定位你的问题、给出可落地的指导。作业可以反复写,相当于反复获得训练。
- 参考他人:如果无从下手,把对应期数的作业页面往下拉,能看到其他训练者提交的作业和批复过程。前人踩过的坑,很可能也是你会遇到的——遇到问题前,先翻翻别人的解决方案,往往能更快开窍。
- 即使没遇到问题,也请简单提交一下作业反馈,这样团队就知道你可以进入下一期了。作业不是为他们做的,这不是应试——作业本身就是训练,是为你自己而做。
- 刘老师团队亲自反馈:团队会逐份批改、解答你在作业里提出的具体问题。我若发现有可补充之处,也会补充回复。
- 反馈时效机制:提交作业后若两个工作日内未收到反馈,请直接联系我的微信(keyanlun)并截屏告知是哪份作业,我会请刘老师尽快处理。
通关全部训练后,你将获得什么?
- 一个有价值的具体选题:深度利用 AI 从领域空白里启发出的、兼具创新性与可行性的综述选题,而非随大流的泛题。
- 一个高相关的专属文献库:100–600 篇精筛文献,且在 Zotero 里被章节标签和唯一编号完全结构化。
- 一份经文献数量验证的可执行大纲:章节分明、每节有料,照着就能写。
- 一篇完整的综述论文终稿:从引言到结论,逐句经过事实核查、原创性重塑,配图与规范引用齐备,可直接投稿。
- 一套可复用的综述论文工作流 + 配套工具箱:这套方法不只写得了这一篇,下一篇、再下一篇都能用。
- 深度人机协同的能力:在符合 AI 使用伦理与学术规范的前提下,真正学会把 AI 当科研助理用——务必注意学术诚信红线。
- 免费获取发票,加微信:yanwenkeyan,或扫下方二维码。
